# ABTest
今天分享的主题是ABTest,接下来围绕什么ABTest、为什么要做ABTest,以及怎么做ABTest来展开今天的分享,希望通过今天的分享, 让大家对ABTest有一个更深入的理解和认识。
# 1、什么是ABTest
ABTest是为同一个产品目标制定多个方案,让一部分用户使用A方案,另一部分用户使用B方案,…,然后通过日志记录用户的使用情况,并通过数据分析相关指标(点击率、转化率等),从而得出更符合设计目标的方案,并最终将流量全部切换至符合目标的方案。
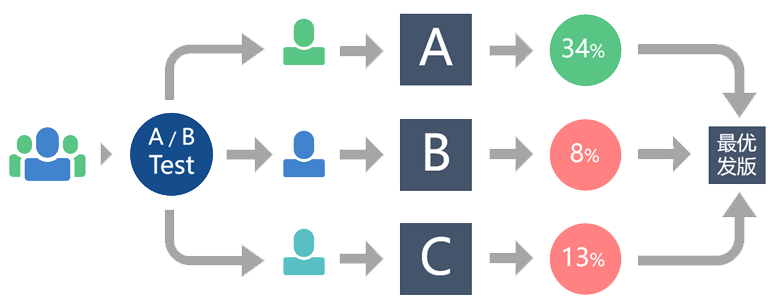
概括来说
ABTest就是对比试验,经过对比、分析得出最优方案
# 2、为什么要做ABTest
1、验证产品的迭代策略是否有效
2、推动业务持续增长


对于运营来说,通过ABTest可以知道哪种运营方式更有效,更能吸引用户。
对于产研来说,通过ABTest可以得出哪种展现方式更能促进用户点击、下单、购买。
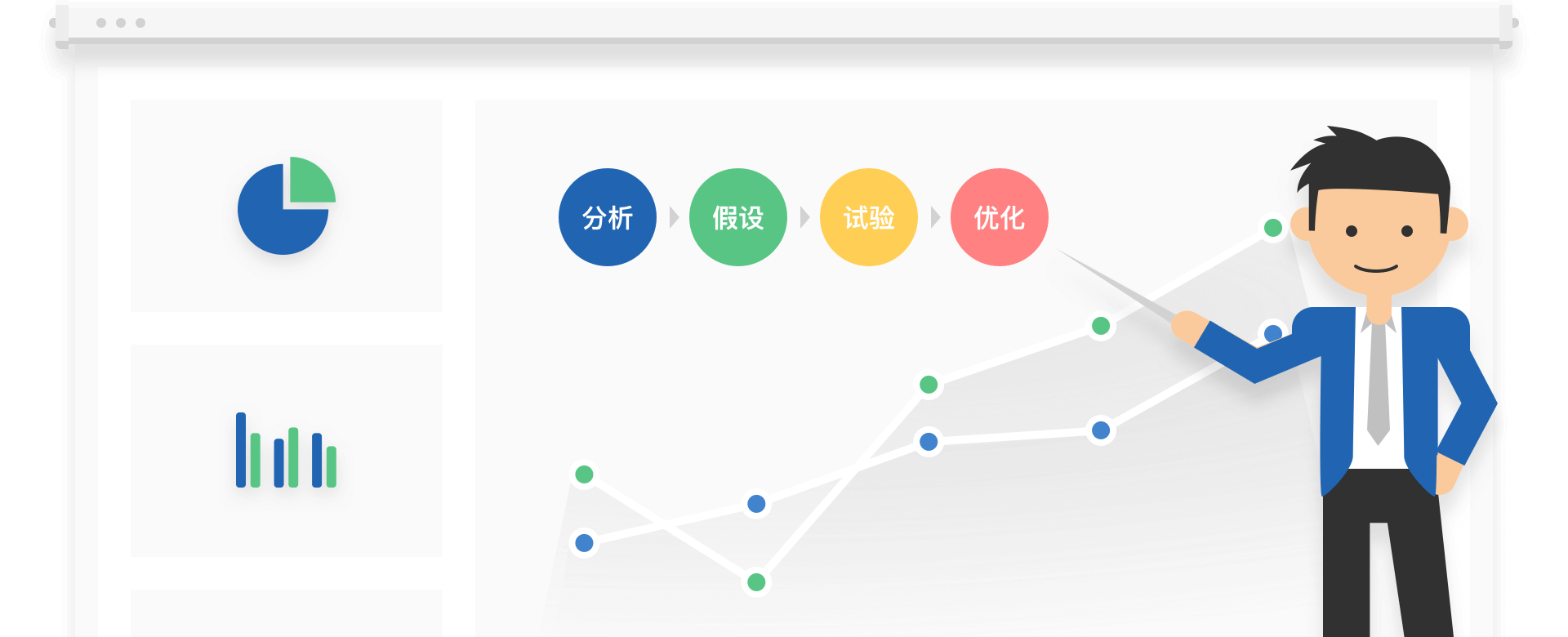
通过分析、假设、试验、优化等流程后,把业务逐步向前推进,不断提升业务指标,增加收益。同时我们也能通过ABTest验证产品策略的有效性,避免走错路。
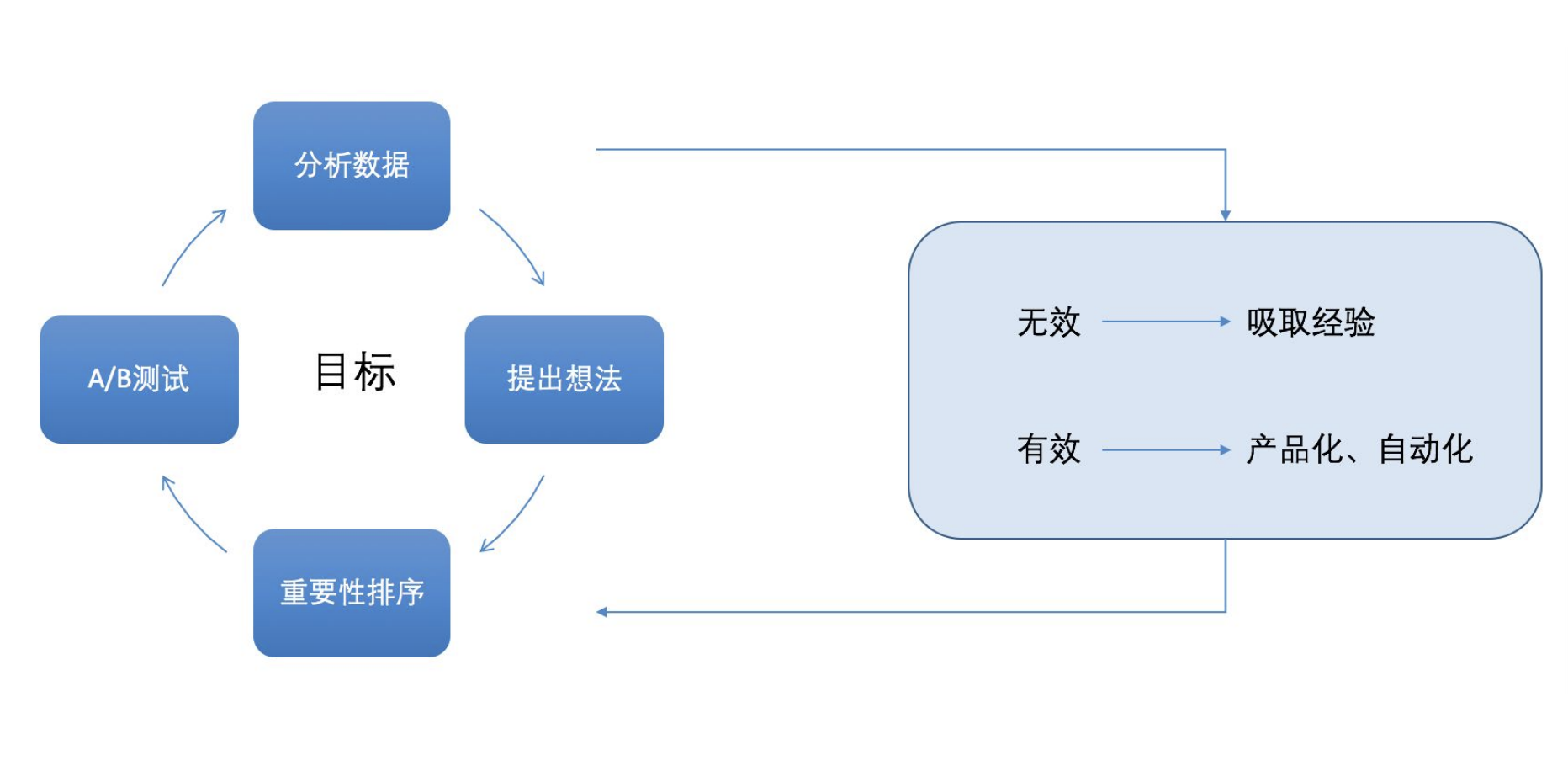
# 3、ABTest理论基础和特性
# 1、ABTest理论基础
基于大数定律和中心极限定理
大数定理就是样本均值在总体数量趋于无穷时依概率收敛于样本均值的数学期望。
中心极限定理就是一般在同分布的情况下,样本值的和在总体数量趋于无穷时的极限分布近似于正态分布
# 2、ABTest的实践基础
(1)、双盲测试
实验组和对照组对实验无感,减少偏见和无意识暗示,保证实验的公平性。
(2)、随机分流
随机分流保证结果的无偏统计。随机分流的前提是流量足够大,否则不能确保流量的随机分配。
通常根据用户设备号+实验id取hash,对100取模来分配流量。通常将流量比例分为50:20:20:10四个版本。
(3)、控制变量
ABTest采用控制变量法来实施实验,一个实验组最好只能有一个自变量,如果有多个自变量无法判断是那个因素的影响。
(4)、AA测试 AA测试用于随机分流后不同用户群体的影响。当AA群体实验结果一致时,认为其他实验效果的差异不是因为分流任务不一致导致的。
(5)、埋点 收集不同版本的实验数据,用于后续的用户行为统计和指标的分析。
(6)、正交实验 当一个页面上有多个实验时,各个实验之间应该相互独立(分流独立、功能独立),避免相互影响。比如一个页面有两处做实验时,应该各自独立分流。
# 3、特性
(1)、先验性(预测型结论)
ABTest不是盲目做实验,因为做实验也是有成本的,我们在做实验的都是以基于已有的结论、经验以及竞品的优点,所以我们在做实验的时候,会预测该方案的效果会好。
既然是基于已有的结论、经验,那为什么还要做ABTest呢,改改直接上线就完呀,实际上并不是这样,别人的效果好在你这就不一定好,这是因为ABTest具有不确定性。
(2)、并行性(环境的一致性,节省时间)
ABTest的实验要求并行来做,因为不同的时间点,用户对页面的反应不同。不在同时时间做实验,实验的可信度不高。而且并行实验可以节约实验周期,缩短实验时间。
(3)、科学性(流量分配的科学性)
科学的流量分配是实验结论准确性的基础,流量的分配涉及到后续的数据分析,流量分配越科学,实验的可信度越高。
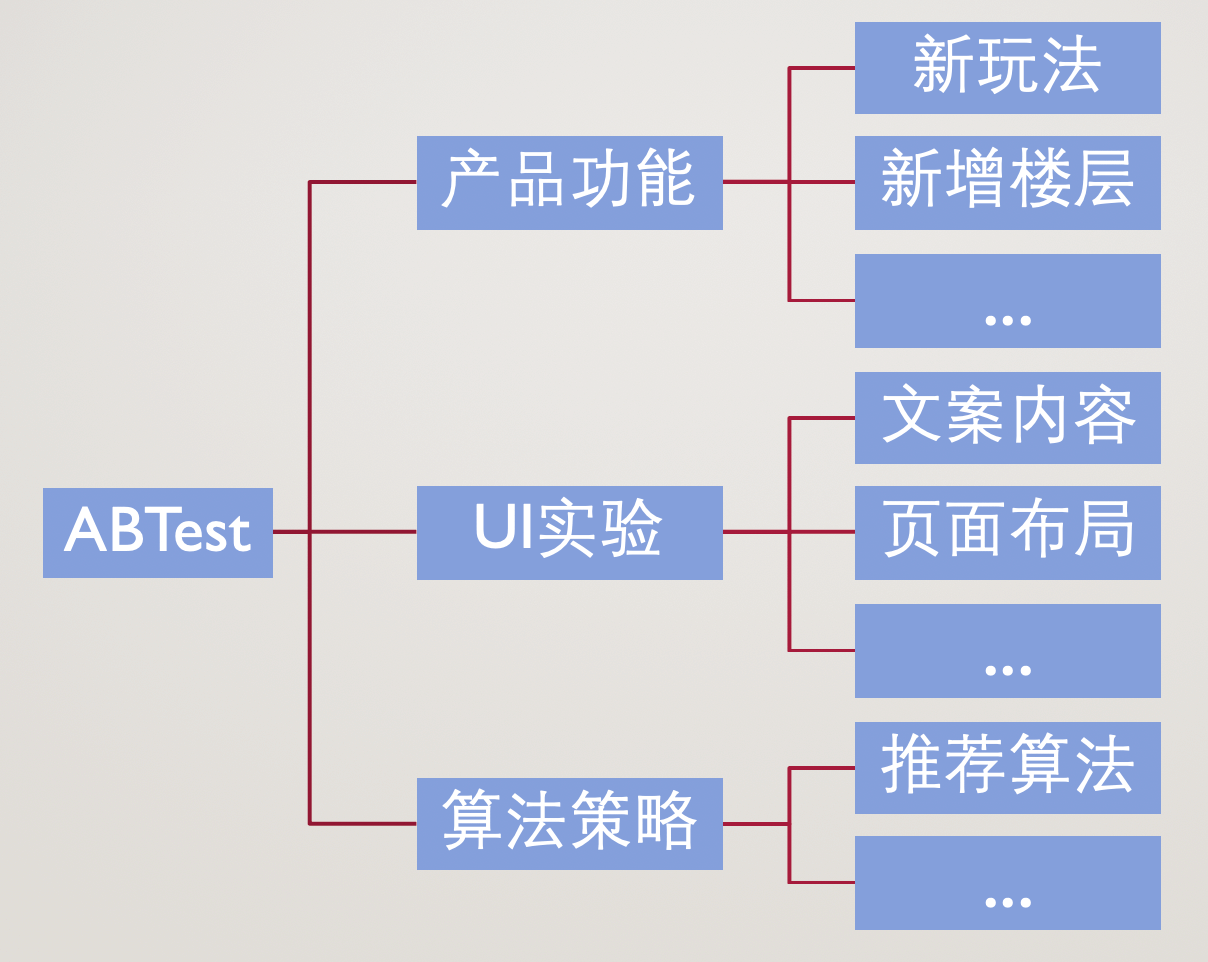
# 4、ABTest的分类
# 5、ABTest的实验条件
1、独立性:相互独立、互不干扰
2、可伸缩性:系统能同时支持多个实验
3、灵活性:不同的配置和不同的流量
4、事先确立评价指标 确立评价指标有利于后续实验数据分析需要重点关注那些指标,常见的有点击率、转化率、展现、曝光、消耗、roi、使用时长等
5、大流量支撑
ABTest是有理论基础的,他的理论基础就是我们在概率论中学习的中心极限定理、大数定理、置信区间以及统计显著性。中心极限定理的含义:样本数量越大,数据就越接近正态分布。大数定理的含义:当样本数趋向于正无穷的时候,样本的平均值就收敛于随机变量的期望,也就是样本数量越大,平均值就会收敛。
流量越大(一般日流量在1000个UV以上),结果越准确,否则很难获得准确(结果收敛)结果,数据量小的话,实验数据波动比较明显,实验指标容易受个体的影响,各项评价指标将很难趋于收敛,进而导致无法得出有效的结论,甚至有可能得出的是错误的结论。
6、分流的均匀性
分流的均匀性是实验结果可靠性的基础
7、实验时长
实验时长的大小不仅影响实验的准确度,而且影响实验的效率。当实验时长过短时,会导致实验结果受短期影响较大;实验较长时,会影响产品迭代效率,那么应该怎样确定实验时长呢?
一般来说,实验时长应该满足以下两个条件:
- 条件1:最少观察一周,工作日与周末的流量是不一致的,为保证实验准确性,建议实验时长大于一周
- 条件2:实验时长 = 总体样本 / 实验组每天的流量,根据实验流量占总体流量的比例来判定,但仍应该满足条件1。
# 6、ABTest的分流过程
# 1、分流策略
ABTest实验的主要环节是分流过程,一个好的ABTest系统需要强大分流的算法支撑。
下图是一个简单的分流策略,当用户访问页面时,由LB(负载均衡)将流量分配到各实验上。

# 2、分流指标
在实验过程中,我们常常按照用户维度来分组,对于命中某种策略的用户分流到对应的实验,经常采用的用户维度有以下几个:
- UID:用户的唯一标识
- DID:设备编号,设备的唯一标识
- CookieID:登录的标识
- SessionID:会话标识
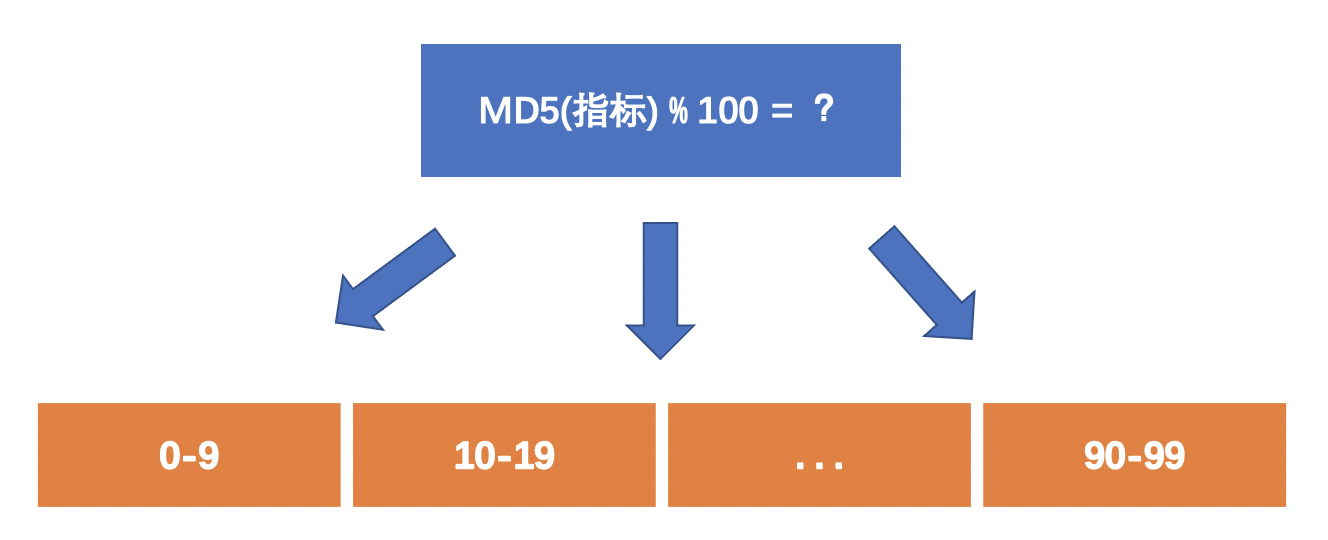
- 这里取对指标取md5值的目的是为了让处理后的指标分布更加随机。
# 3、分流方法
在实际情况中,我们可能出现多个实验并行进行的情况,为了避免实验之间相互影响,我们往往采用正交的方式进行分流,使得各个实验的分流相互独立,避免各实验间相互干扰。
在分流指标上,我们往往采用UID方式进行分流,如果所有的实验都采用UID的方式分组,会存在组间实验交叉的情况,为避免这个情况的处理,在取hash值时,为每个实验加上层数,这样即可将各个实验分开。
正交实验:Md5(UID + LayerID) % N:保证每个实验的分流相互独立,互不影响
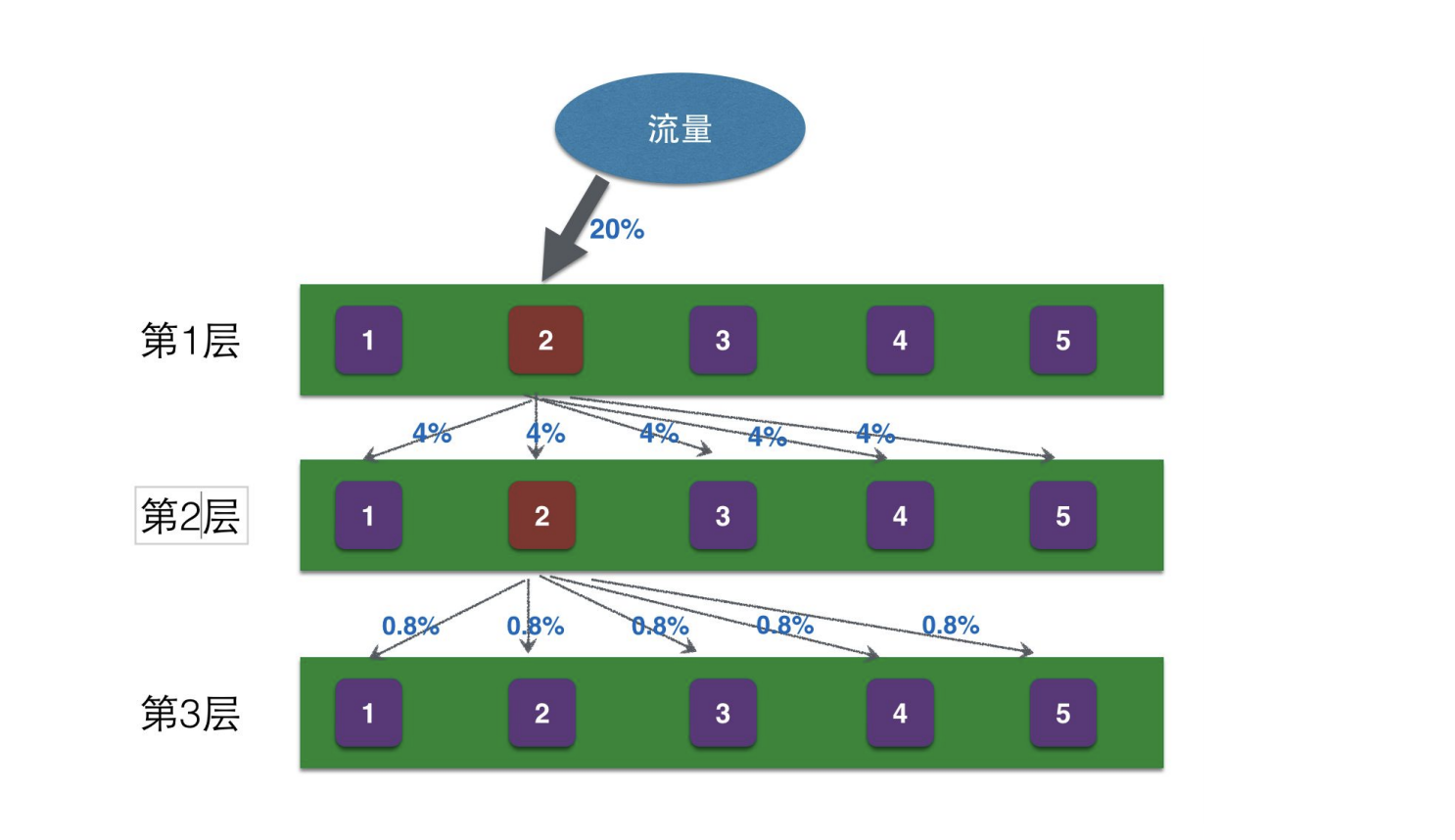
# 4、触发时机
流量的触发时机:在用户体验产生差异的时候才触发实验,避免过早暴露,否则会影响实验准确性。
# 7、实验数据分析
随着ABTest实验的深入,也需要有数据分析平台的支持,进而提升数据分析的效率和准确率。
这里对数据分析的大致过程做简要的介绍。
(1)、获取原始数据
注:以下数据为模拟数据,非真实数据
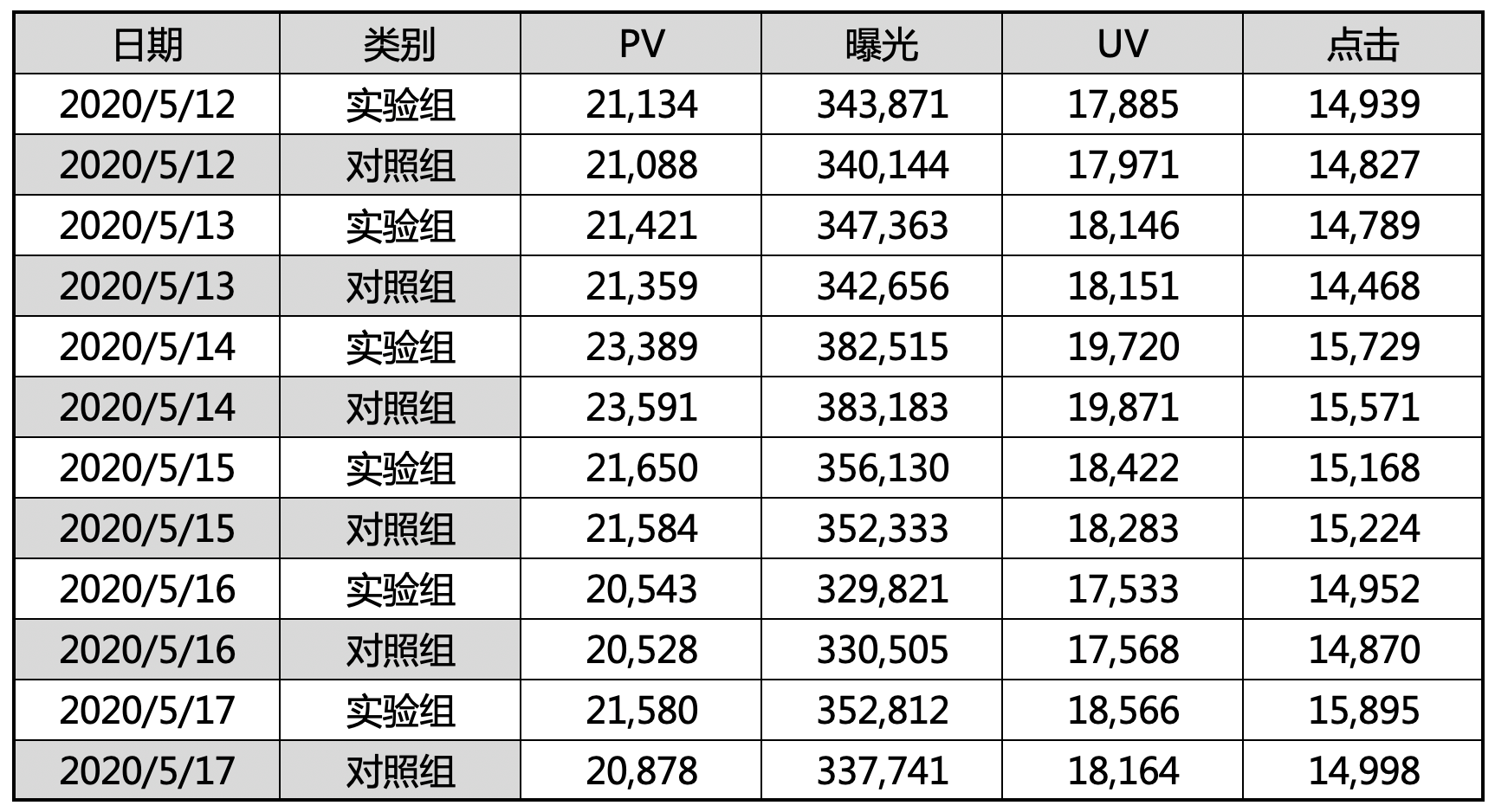
(2)、计算平均值

(3)、归一化
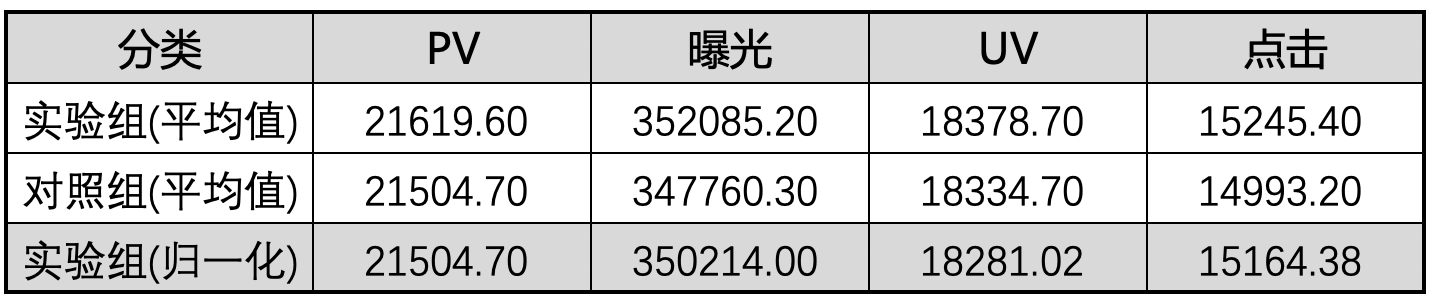
(4)、计算相对值
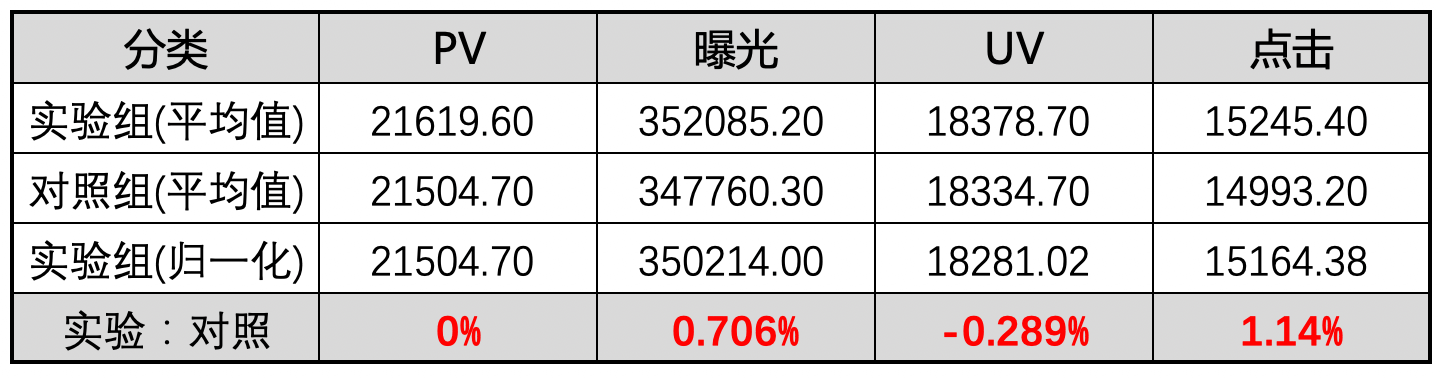
如何判断指标变化是否可信 —— 假设检验
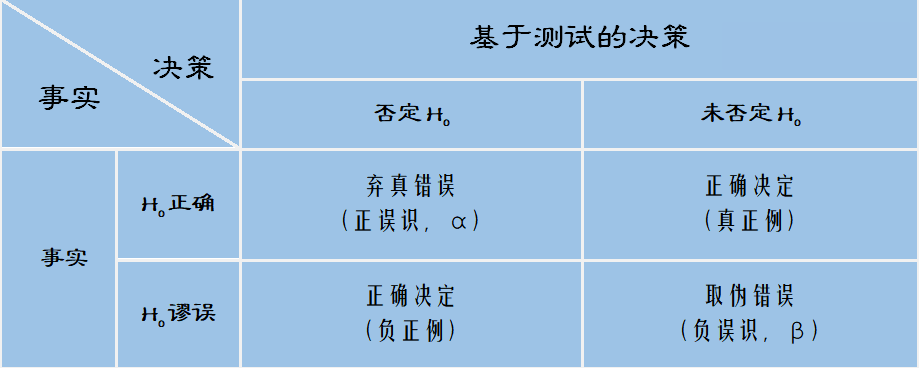
弃真错误:实际上指标没有优化,但误解读为有优化
取伪错误:实际上指标有优化,但误解读为没优化
降低弃真错误的概率,会导致取伪错误变高,反之亦然。
在实际的产品迭代中,发生取伪错误的后果比弃真错误更严重。
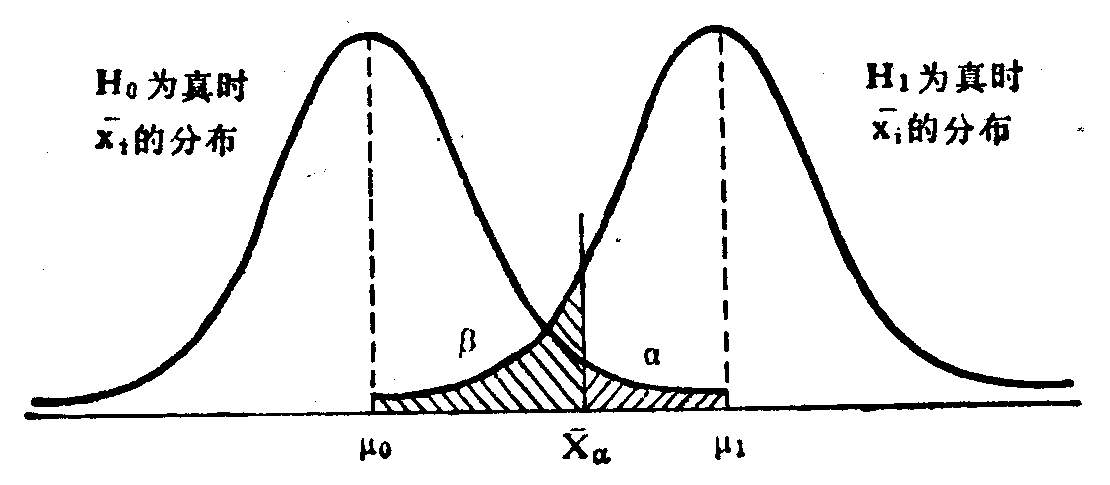
α:表示发生弃真错误的概率
β:表示发生取伪错误的概率
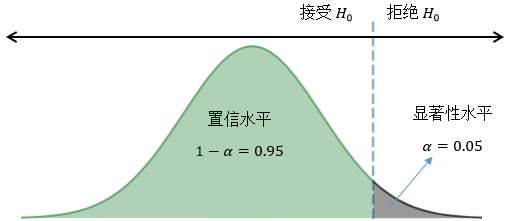
P值:用来衡量量指标计算结果的显著性,数据说有用但实际上没用的概率
实验结果的变化不一定是最终的实验结论,这是因为各项指标在没做实验也会在一定的范围波动,经过概率论公式的计算,可以得出各指标的置信区间,也就是说当变化的指标在置信区间内变化时,我们认为实验对该项指标的变化不明显,当实验指标超出执行区间时,我们认为实验的变化会有影响该指标,根据变化值的大小得出影响力的深浅。
(6)、得出结论,总结原因,整理文档
经过置信区间的比对处理后,我们认为数据结果是可行的,进而可以得出实验结论。
通过各项指标的变化,我们可以对整个实验过程做详细的分析,进而得出由实验条件变化引起用户行为的变化,为指导后续实验做经验参考,为业务指标的持续增长做理论支持
# 8、ABTest存在的问题
- 1、多数ABTest都将废弃
大多数的实验效果不是正向的,ABTest做的越多,对业务优化的点越多,随着ABTest的深入,再进一步优化的可能性就比较小了,很难再有提升。
2、全量、小流量的相互切换,频繁的上下线,容易出现线上问题
3、代码的版本管理
4、照顾到用户体验的问题,同一用户看到的页面相同
5、ABTest的时间:主要看实验结果是否趋于收敛,实验数据收敛与访问量有关
# 9、ABTest的应用场景
1、广告落地页
2、广告投放与管理
3、灰度发布
4、APP用户体验

← 持续集成、持续交付、持续部署 埋点 →